
Why SGVR Cluster?
Welcome to the SGVR Cluster. Our platform harnesses the power of numerous GPUs, significantly enhancing the training, evaluation, and deployment of ML models and applications. At the heart of SGVR Cluster lies Kubernetes, an open-source container orchestration system known for its exceptional scalability and flexibility. This foundation enables us to maximize the efficiency of our computing resources.
The SGVR Cluster offers researchers flexibility in constructing their ML environments, thanks to the integration of Docker, a tool that has gained widespread adoption in the machine learning community. Within our cluster, applications – whether they’re for training, evaluation, or demonstration – can effortlessly scale to dozens of nodes. This scalability is facilitated through the use of container technology, ensuring a rapid and efficient research cycle.
What’s Inside

With the SGVR Cluster, a user can scale up their ML apps to dozens of GPUs in our cluster, following each step.
- Define ML apps with Docker. A user can push a Dockerized app to our own Docker registry.
- Store Dataset. We have built more than 200TB of network storage, which is connected via a private 10Gbps network. Data is accessible throughout the cluster.
- Deploy ML apps with Kubernetes. Push your highly-flexible job configuration yaml to our cluster, including running commands, data storage mounts, and required resources (e.g. #GPUs).
- Monitor ML apps. Grafana and exposed ports allow you to monitor your running apps.
Define ML apps with Docker
We have our own Docker registry. Build and push your executable container. Then the app is ready to be deployed in our cluster.

Store Dataset
Powered by Synology, we have built more than 200 TB of data storage which is connected to the cluster with a 10Gbps private network. We can easily browse the files with a GUI-enabled web interface or a directory directly mounted to a user’s development environment.
Deploy ML apps with Kubernetes
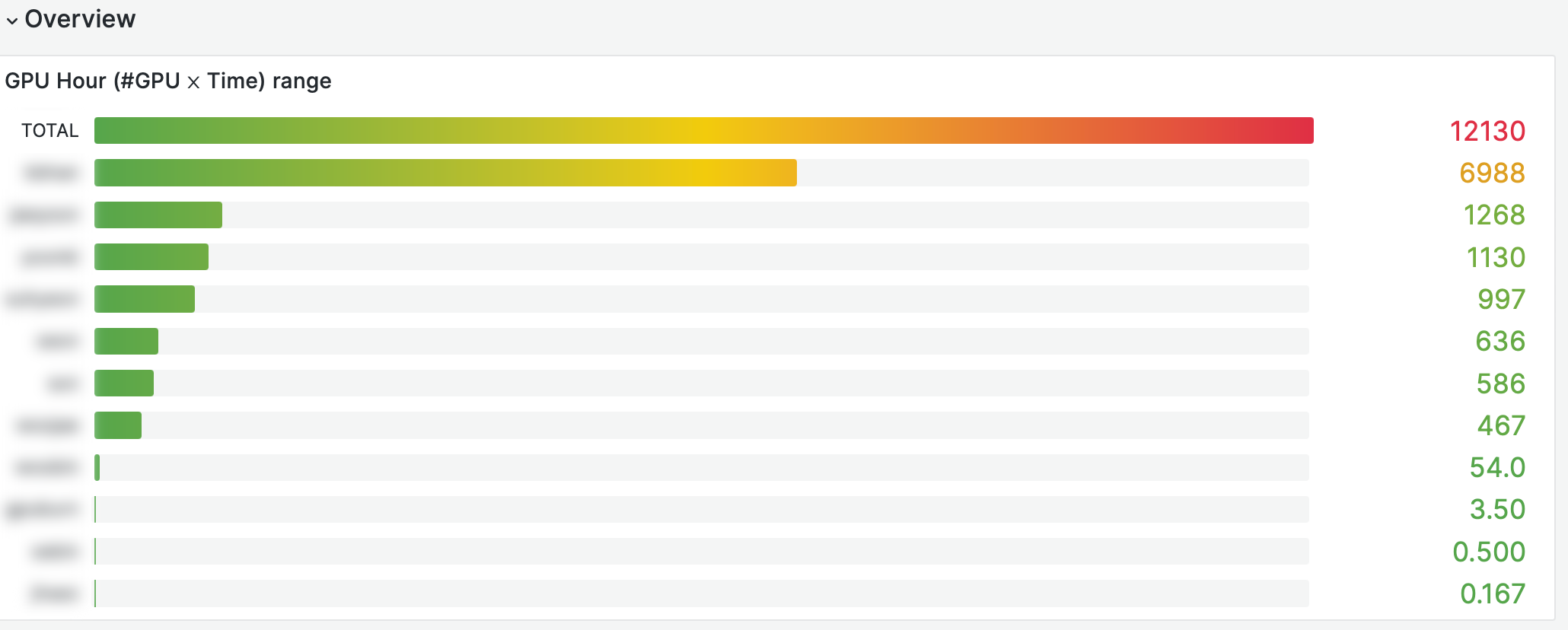
A user can seamlessly deploy an application using Kubernetes orchestration by submitting a job batch that references Docker applications they have uploaded. This job batch offers significant flexibility, allowing the user to specify various resources such as the number of CPUs, the amount of memory, the number of GPUs, and the types of GPUs needed for the task. As demonstrated in the diagram above, it’s possible to scale an application effectively, achieving up to 7,000 (or more) GPU hours over a two-week period. This capability is particularly advantageous for empirical machine learning studies that require substantial computational resources.
Monitor ML apps
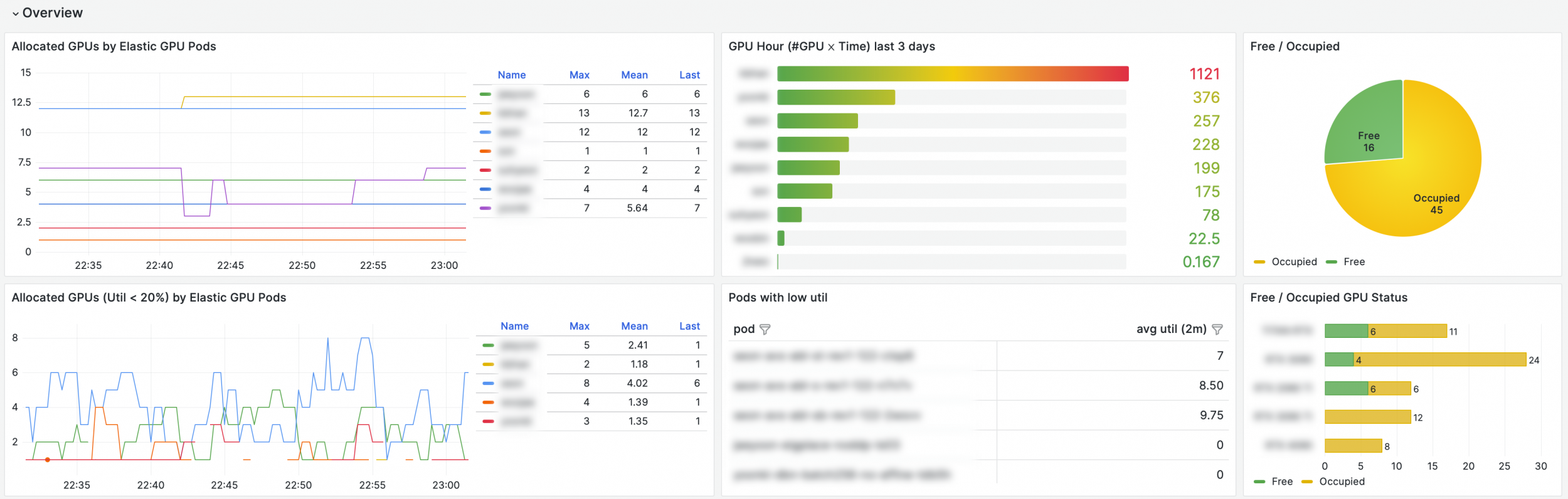
To assist the ML research, we have built a monitoring system with Grafana. A user can monitor status and resource usage of their running apps. Additionally, it helps a fair resource distribution for lab members.To support machine learning research, we have implemented a Grafana-based monitoring system. This tool enables users to track the status and resource consumption of their active applications. It also facilitates equitable distribution of resources among lab members, ensuring efficient and fair usage.
For cluster administrators, this monitoring system is invaluable for identifying and addressing issues with applications and nodes. It includes an integrated notification feature that sends urgent alerts to our Discord channel. A practical application of this system is its use in informing node managers about malfunctioning or failed nodes, ensuring prompt attention and resolution.
