IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2022
Person Re-identification
Yoonki Cho,
Woo Jae Kim
Seunghoon Hong, and
Sung-Eui Yoon
Korea Advanced Institute of Science and Technology (KAIST)
[Paper] [Code]
Video
Abstract
Unsupervised person re-identification (re-ID) aims at learning discriminative representations for person retrieval from unlabeled data. Recent techniques accomplish this task by using pseudo-labels, but these labels are inherently noisy and deteriorate the accuracy. To overcome this problem, several pseudo-label refinement methods have been proposed, but they neglect the fine-grained local context essential for person re-ID. In this paper, we propose a novel Part-based Pseudo Label Refinement (PPLR) framework that reduces the label noise by employing the complementary relationship between global and part features. Specifically, we design a cross agreement score as the similarity of k-nearest neighbors between feature spaces to exploit the reliable complementary relationship. Based on the cross agreement, we refine pseudo-labels of global features by ensembling the predictions of part features, which collectively alleviate the noise in global feature clustering. We further refine pseudo-labels of part features by applying label smoothing according to the suitability of given labels for each part. Thanks to the reliable complementary information provided by the cross agreement score, our PPLR effectively reduces the influence of noisy labels and learns discriminative representations with rich local contexts. Extensive experimental results on Market-1501 and MSMT17 demonstrate the effectiveness of the proposed method over the state-of-the-art performance.
Overview
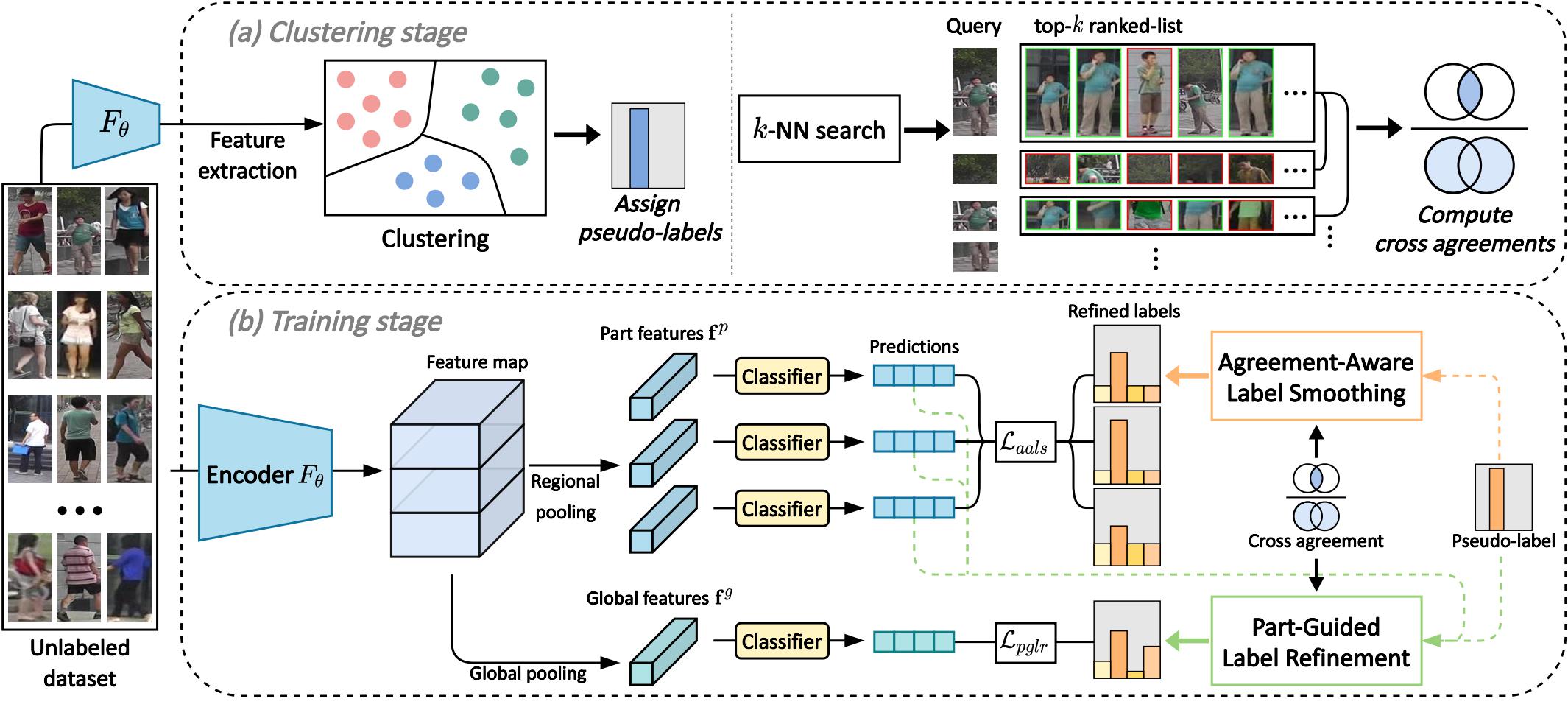
The illustration of Part-based Pseudo Label Refinement (PPLR) framework. PPLR alternates the clustering stage and the training stage. (a) In the clustering stage, we assign pseudo-labels by clustering the global features on the unlabeled dataset. We then perform a k-nearest neighbor search on each feature space and compute the cross agreement score based on the similarity between the top-k ranked lists of the global and part features. (b) In the training stage, we train the model with refined pseudo-labels based on the cross agreement score. We smooth the labels of part features according to the cross agreement score of each part and refine the labels of global features by aggregating the part features' predictions.
Experimental Results