IEEE International Conference on Image Processing 2022
for Transferable Adversarial Attacks
Woo Jae Kim,
Seunghoon Hong, and
Sung-Eui Yoon
Korea Advanced Institute of Science and Technology (KAIST)
[Paper] [Code] [Slides]
Video
Abstract
Adversarial attacks with improved transferability — the ability of an adversarial example crafted on a known model to also fool unknown models — have recently received much attention due to their practicality. Nevertheless, existing transferable attacks craft perturbations in a deterministic manner and often fail to fully explore the loss surface, thus falling into a poor local optimum and suffering from low transferability. To solve this problem, we propose Attentive-Diversity Attack (ADA), which disrupts diverse salient features in a stochastic manner to improve transferability. Primarily, we perturb the image attention to disrupt universal features shared by different models. Then, to effectively avoid poor local optima, we disrupt these features in a stochastic manner and explore the search space of transferable perturbations more exhaustively. More specifically, we use a generator to produce adversarial perturbations that each disturbs features in different ways depending on an input latent code. Extensive experimental evaluations demonstrate the effectiveness of our method, outperforming the transferability of state-of-the-art methods.
Motivations
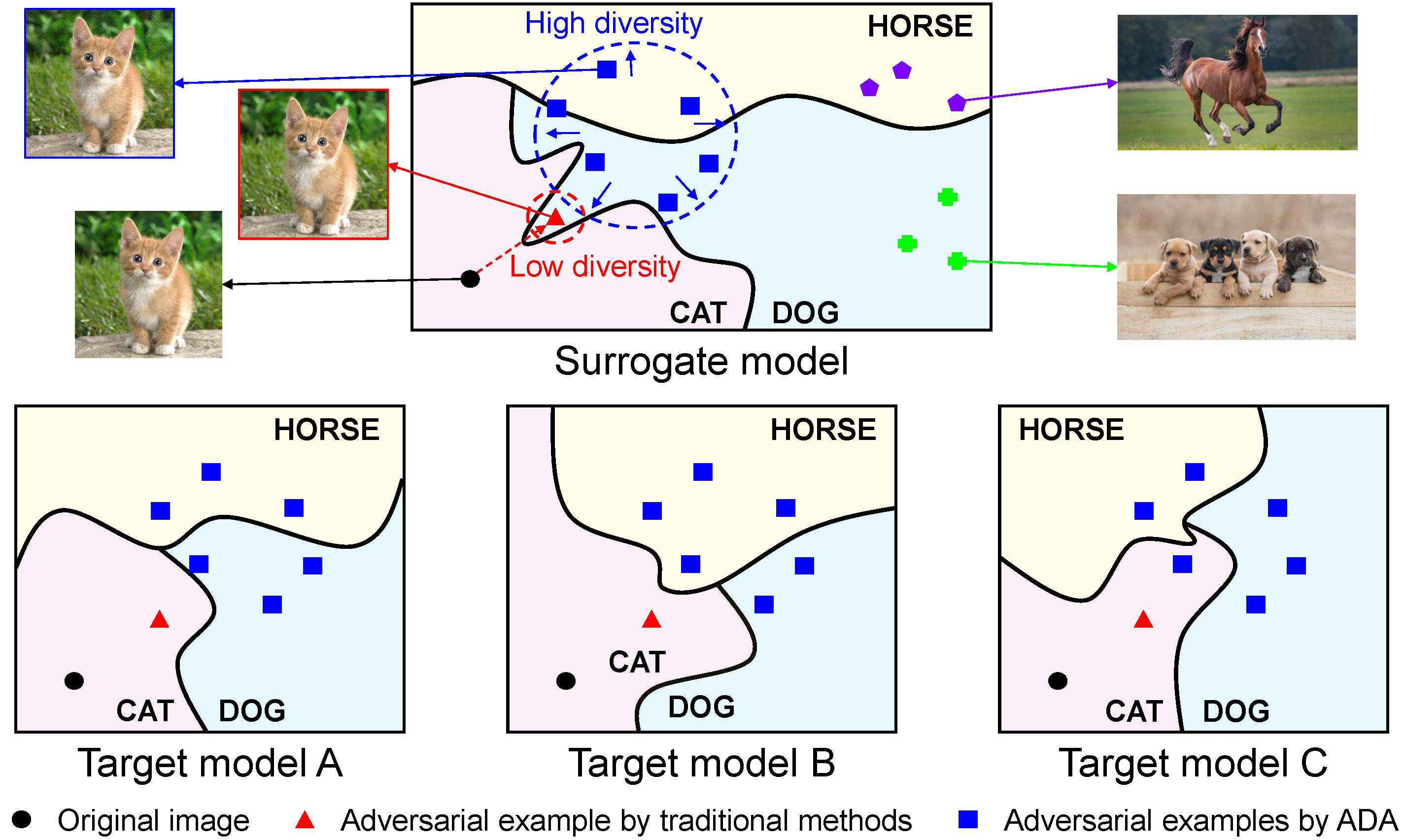
Schematic illustration of adversarial examples crafted by traditional methods and our method (ADA) along the class decision boundaries of the surrogate model and the target models. With lack of diversity, traditional methods greedily craft a deterministic adversarial example that easily falls into a poor local optimum and thus overfits to the surrogate model. In contrast, our method explores the search space of adversarial examples more exhaustively by generating diverse perturbations and avoids such local optimum.
Overview
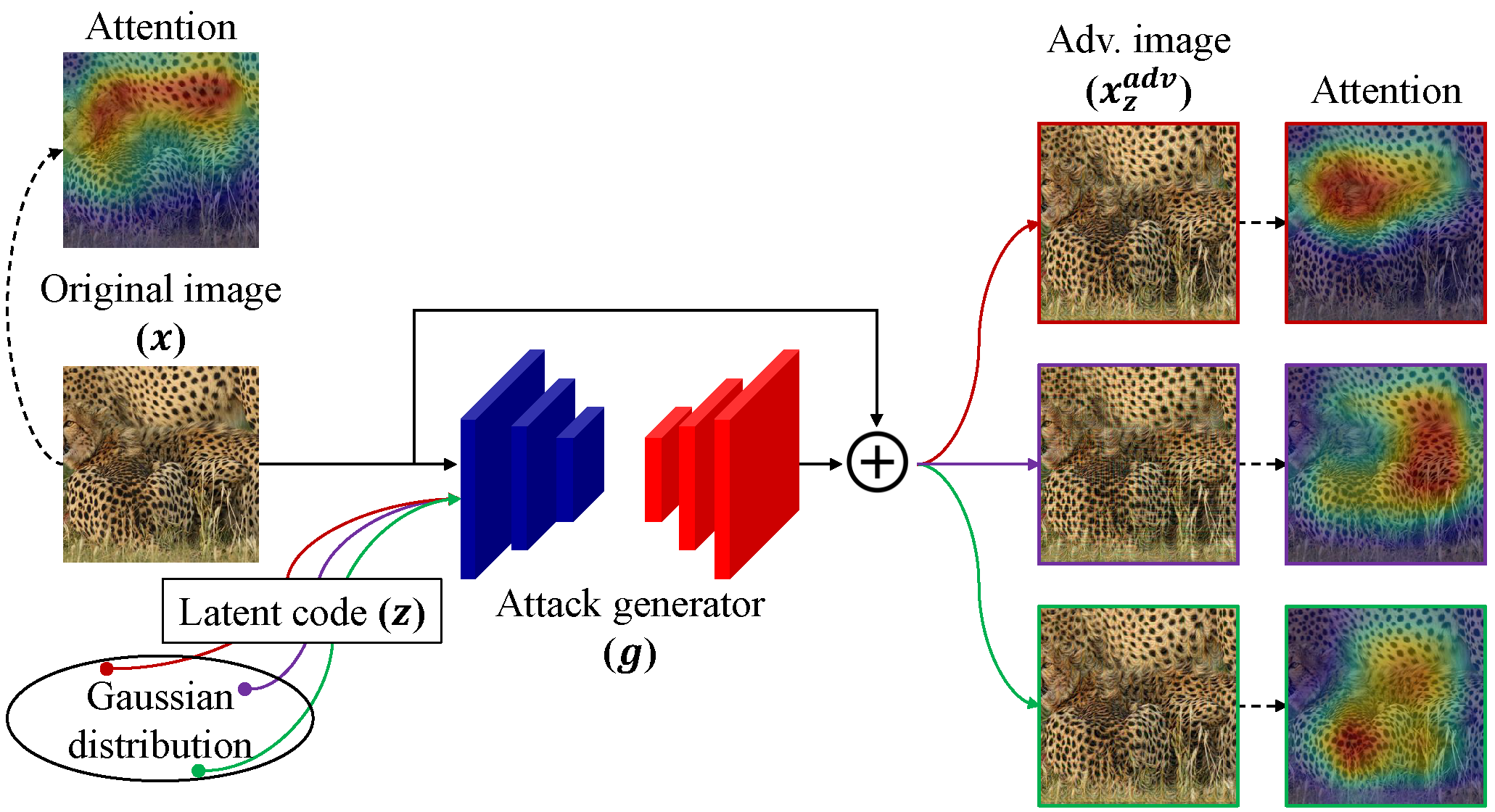
Overview of our proposed Attentive-Diversity Attack (ADA). Given an image and a latent code, the attack generator produces a perturbation that disrupts the image attention in a diverse manner.
Experimental Results
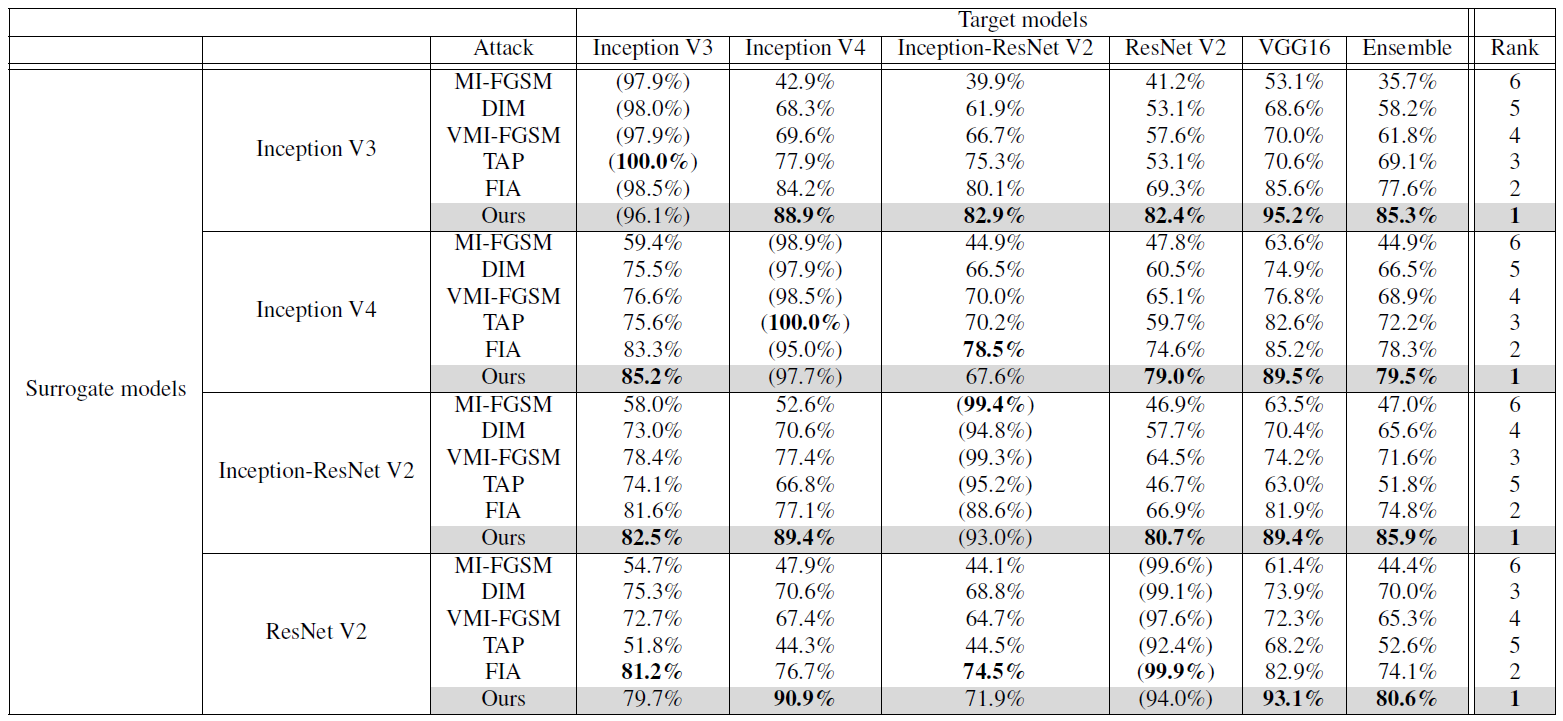
Attack success rates (ASR) of different attacks against various target models.
The leftmost column and the uppermost row show surrogate models and target models, respectively.
Parentheses () indicates white-box attack where the target model is the surrogate model.
Best results are highlighted in bold, and Rank
denotes the order of highest average ASR on black-box models.