
IEEE International Conference on Robotics and Automation (ICRA) 2022
Implicit LiDAR Network: LiDAR Super-Resolution via Interpolation Weight Prediction
by Youngsun Kwon, Minhyuk Sung, and Sung-Eui Yoon
Korea Advanced Institute of Science and Technology (KAIST)
Abstract
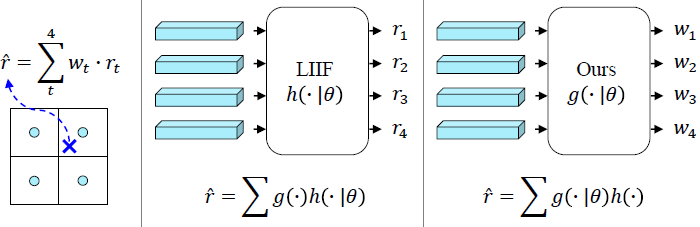
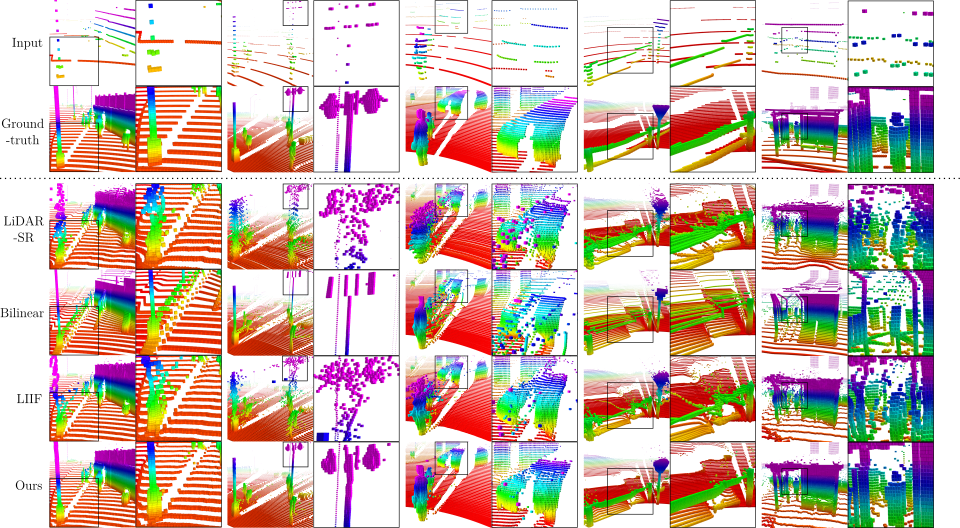
Super-resolution of LiDAR range images is crucial to improving many downstream tasks such as object detection, recognition, and tracking. While deep learning has made a remarkable advances in super-resolution techniques, typical convolutional architectures limit upscaling factors to specific output resolutions in training. Recent work has shown that a continuous representation of an image and learning its implicit function enable almost limitless upscaling. However, the detailed approach, predicting values (depths) for neighbor pixels in the input and then linearly interpolating them, does not best fit the LiDAR range images since it does not fill the unmeasured details but creates a new image with regression in a high-dimensional space. In addition, the linear interpolation blurs sharp edges providing important boundary information of objects in 3-D points. To handle these problems, we propose a novel network, Implicit LiDAR Network (ILN), which learns not the values per pixels but weights in the interpolation so that the super-resolution can be done by blending the input pixel depths but with non-linear weights. Also, the weights can be considered as attentions from the query to the neighbor pixels, and thus an attention module in the recent Transformer architecture can be leveraged. Our experiments with a novel large-scale synthetic dataset demonstrate that the proposed network reconstructs more accurately than the state-of-the-art methods, achieving much faster convergence in training.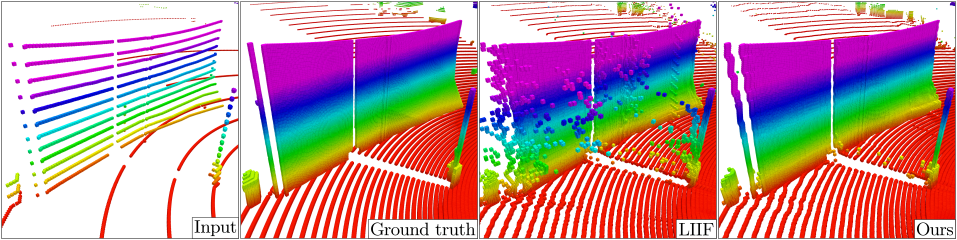
Contents
Paper: PDF(5.1MB)Source code: Github
Presentation: Video(117MB), PPT(48.7MB)
Bibtex:
@article{kwon2022implicit,
title={Implicit LiDAR Network: LiDAR Super-Resolution via Interpolation Weight Prediction},
author={Kwon, Youngsun and Sung, Minhyuk and Yoon, Sung-Eui},
booktitle={2022 IEEE International Conference on Robotics and Automation (ICRA)},
year={2022},
organization={IEEE}
}