ACM SIGGRAPH Symposium on Interactive 3D Graphics and Games (I3D) 2023
Proceedings of the ACM on Computer Graphics and Interactive Techniques
Kyu Beom Han1,
Olivia G. Odenthal2,
Woo Jae Kim1, and
Sung-Eui Yoon1
Korea Advanced Institute of Science and Technology (KAIST), Republic of Korea1
University of Stuttgart, Germany2
Paper(Author's Version)
Paper(ACM's Version)
Code (Github)
Interactive Viewer (Supplementary Material)
Slides (I3D 2023)

Abstract
Auxiliary features such as geometric buffers (G-buffers) and path descriptors (P-buffers) [Cho et al. 2021] have been shown to significantly improve Monte Carlo (MC) denoising. However, recent approaches implicitly learn to exploit auxiliary features for denoising, which could lead to insufficient utilization of each type of auxiliary features. To overcome such an issue, we propose a denoising framework that relies on an explicit pixel-wise guidance for utilizing auxiliary features. First, we train two denoisers, each trained by a different auxiliary feature (i.e., G-buffers or P-buffers). Then we design our ensembling network to obtain per-pixel ensembling weight maps, which represent pixel-wise guidance for which auxiliary feature should be dominant at reconstructing each individual pixel and use them to ensemble the two denoised results of our denosiers. We also propagate our pixel-wise guidance to the denoisers by jointly training the denoisers and the ensembling network, further guiding the denoisers to focus on regions where G-buffers or P-buffers are relatively important for denoising. Our result and show considerable improvement in denoising performance compared to the baseline denoising model using both G-buffers and P-buffers.
Overview
Pixel-wise Guidance Framework
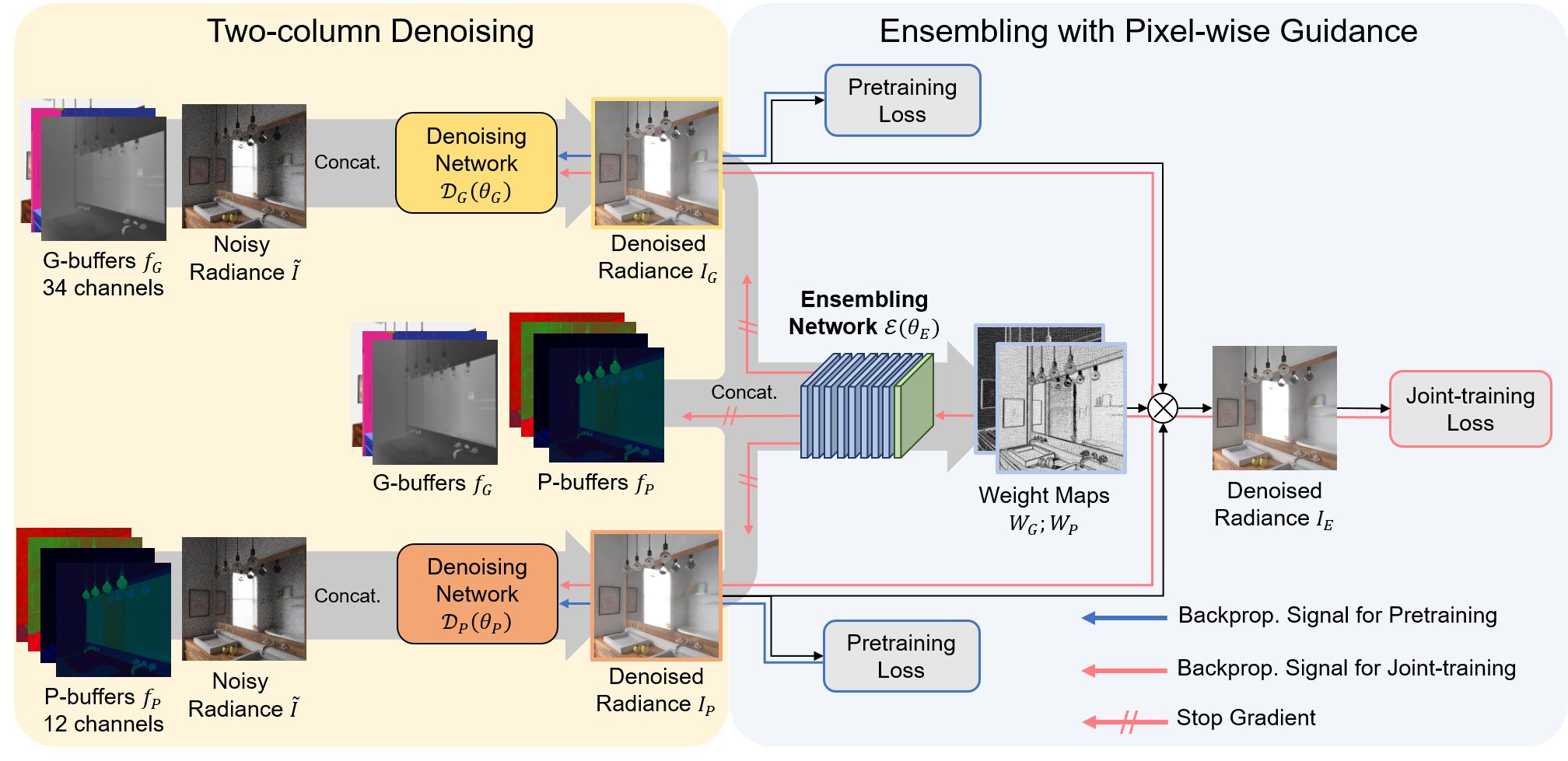
Two pretrained denoising networks denoise the noisy image using single type of auxiliary features.
Then the ensembling network combines the two denoised results via pixel-wise weight maps.
Our framework can utilize any deep learning based MC denoiser as the baseline for our two-column framework.
Joint-training
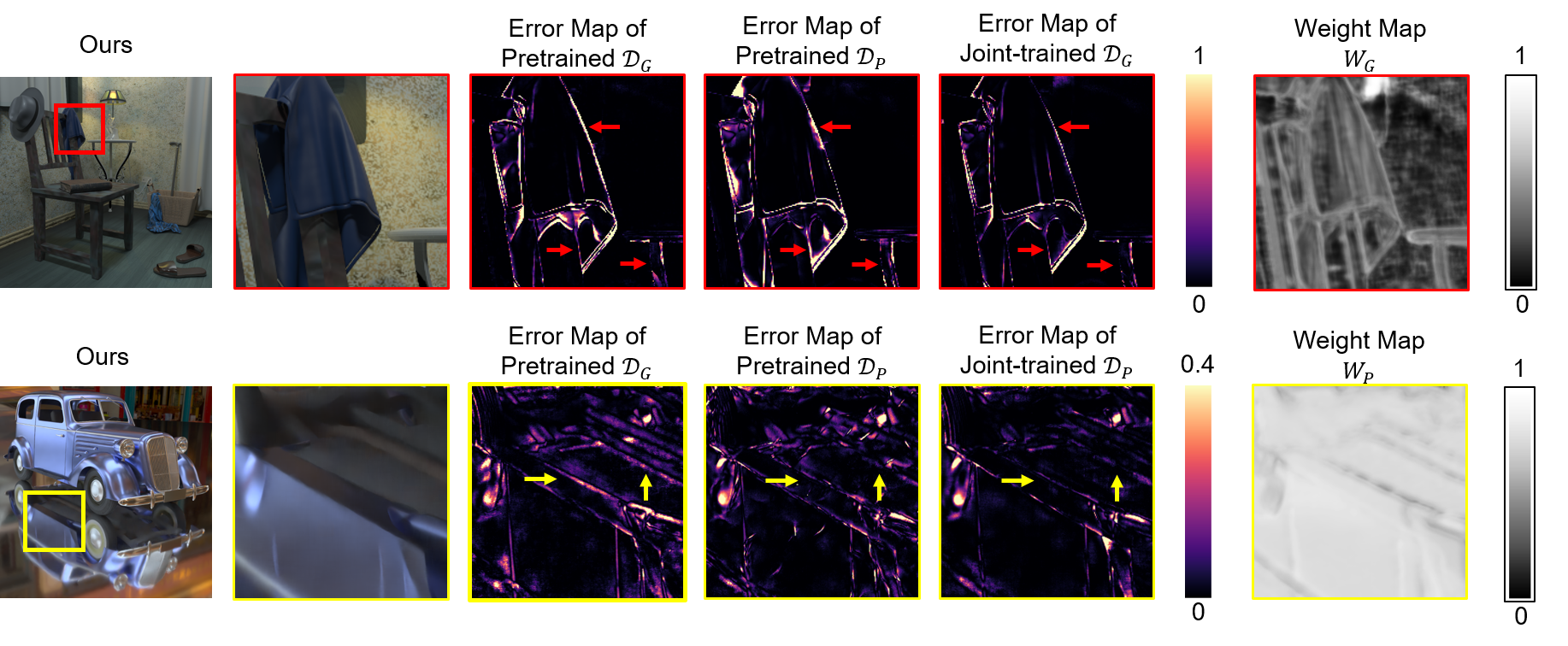
Jointly training the ensembling network and the denoising networks provides per-pixel guidance
through weight maps. The weight maps serves as an importance map of utilizing each type of auxiliary features,
enhancing the denoiser to focus on denoising the pixels with higher weights.
Numerical Results
Comparison with Baseline
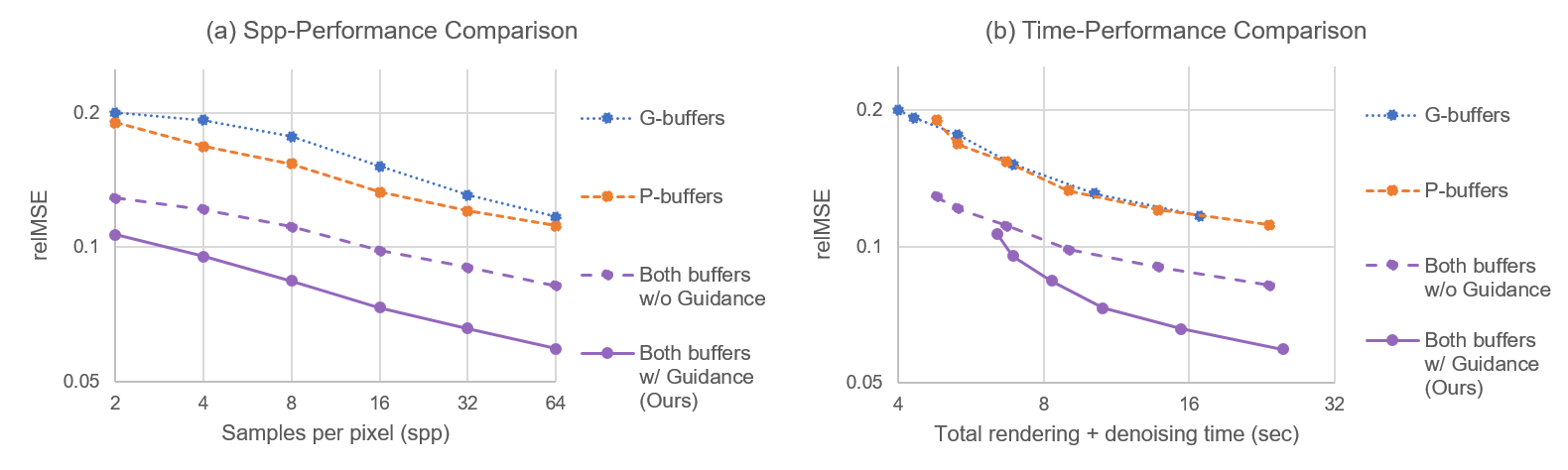
Applying our work to the baseline [Bako et al. 2017] outperforms the baseline denoising networks on all noise levels (i.e. 2~64 samples per pixels, left plot) and in total time (right plot).
Analysis on Computational Cost
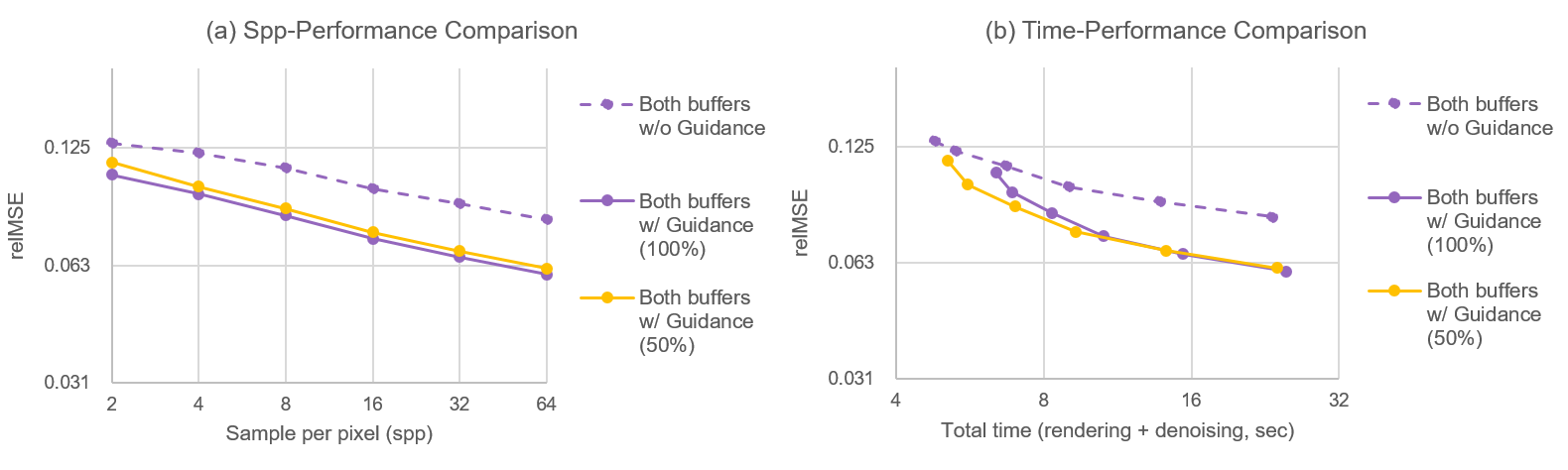
Reducing the number of learnable parameters of our framework shows slightly reduced test performance on all noise levels. However our reduced framework still shows lower numerical error than the baseline model and also shows better time-performance efficiency (right plot).
Visual Results
References
[Cho et al. 2021] Cho, In-Young, Yuchi Huo, and Sung-Eui Yoon. "Weakly-supervised contrastive learning in path manifold for Monte Carlo image reconstruction." ACM Trans. Graph. 40.4 (2021): 38-1.