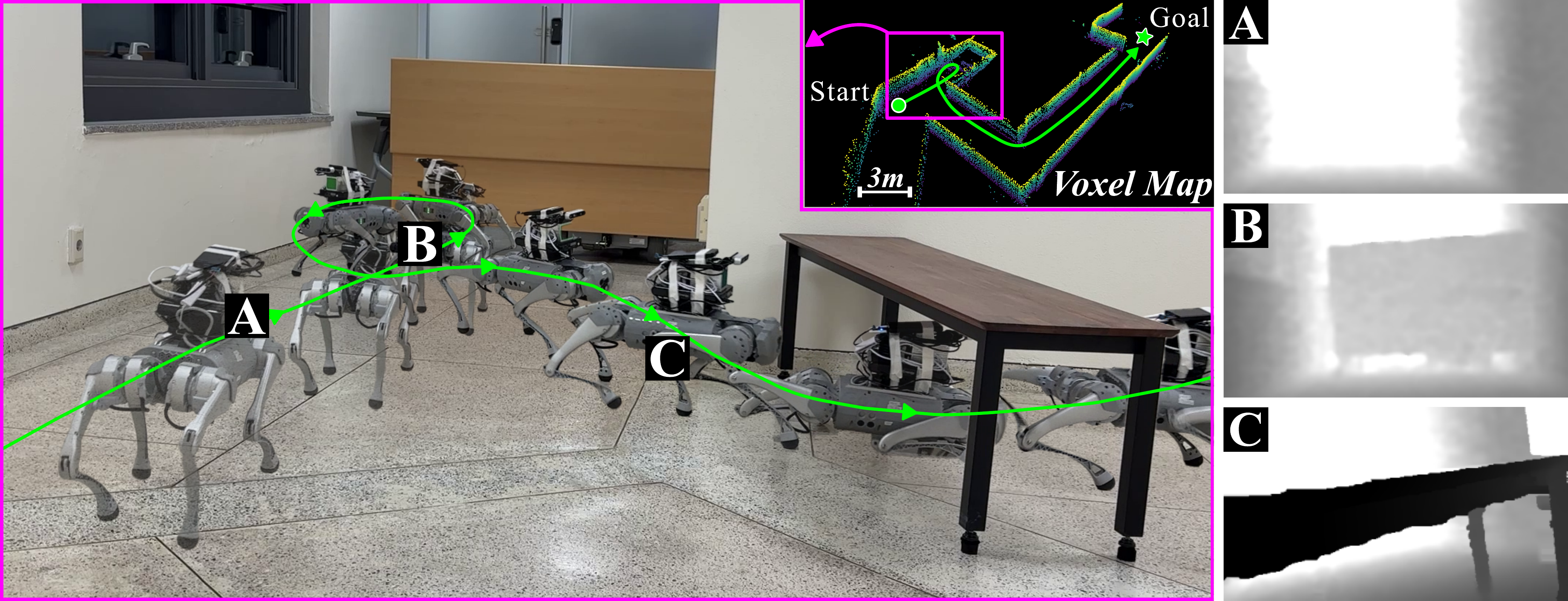
HiPAN in action. Using only onboard depth, the robot backtracks after entering a dead-end corridor (A, B) and adaptively adjusts its posture to pass under a height-constrained passage (C).
The voxel map is shown for visualization only.
Abstract
Navigating quadruped robots in unstructured 3D environments requires goal-directed motion, exploration to escape local minima, and posture adaptation to traverse narrow, height-constrained spaces. Conventional 3D mapping–planning pipelines suffer from accumulated perception errors and high computational overhead on resource-constrained platforms.
We propose HiPAN, a hierarchical framework that operates directly on onboard depth images at deployment. A high-level policy issues strategic navigation commands—planar velocity and body posture—executed by a low-level, posture-adaptive locomotion controller. To mitigate myopic behavior, we introduce Path-Guided Curriculum Learning (PGCL), progressively extending the navigation horizon so the robot first masters reactive avoidance and later develops long-horizon strategies. HiPAN outperforms classical and end-to-end RL baselines in simulation and transfers robustly to diverse indoor and outdoor environments.
Key Contributions
01 · FRAMEWORK
Hierarchical Posture-Adaptive Control
High-level policy outputs velocity and body posture commands directly from depth; low-level policy executes them with adaptive whole-body motion.
02 · LEARNING
Path-Guided Curriculum Learning
Progressively removes intermediate sub-goals along a privileged path, extending the navigation horizon and fostering non-greedy exploration.
03 · SIM RESULTS
96.5% SR · 88.7 SPL
Averaged across four unstructured 3D benchmarks, outperforming classical (56.1% / 41.7) and end-to-end (53.7% / 48.4) baselines.
04 · REAL WORLD
Deployment on Unitree Go1
Onboard RealSense D435i and NUC; robust across cluttered indoors, dead-end corridors, abrupt illumination changes, and outdoor sunlight.
Framework Overview
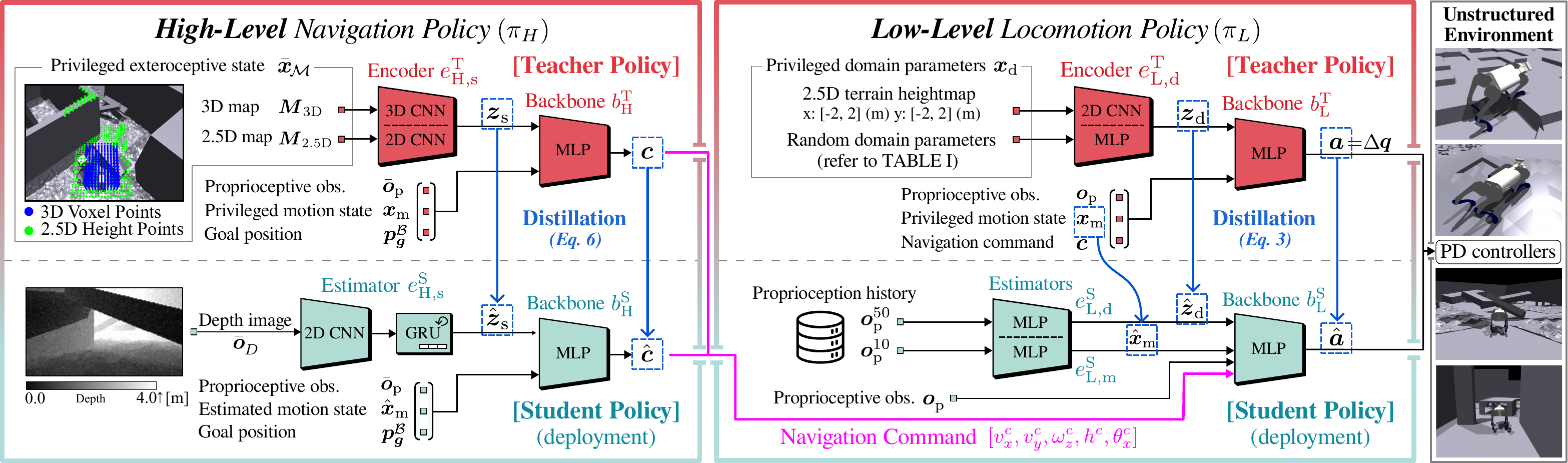
Two-level hierarchy trained stage-wise. Teacher policies (red) are optimized with privileged inputs via PPO; student policies (cyan) are distilled with DAgger and rely only on onboard depth and proprioception at deployment. The high-level policy emits a 5-D command c = [vx, vy, ωz, h, θx], executed by the posture-adaptive low-level controller.
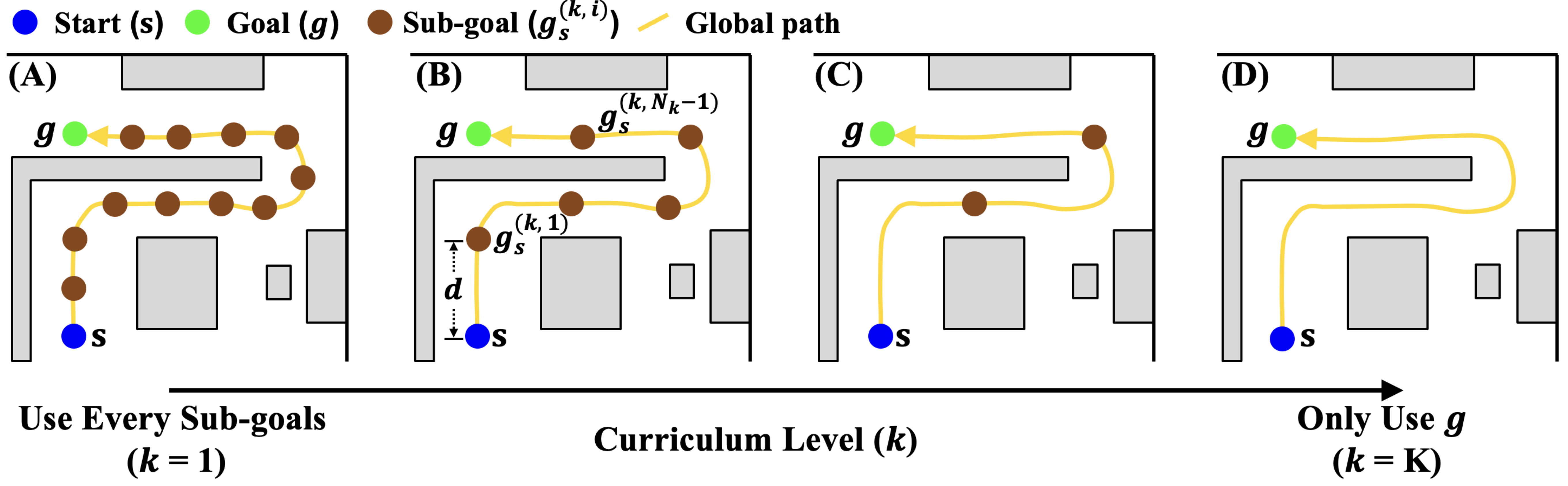
Path-Guided Curriculum Learning
Early stages provide dense sub-goals along a privileged global path (A), teaching reactive avoidance. As curriculum level increases, sub-goals thin out (B, C) until only the final goal remains (D), forcing the agent to learn long-horizon, non-greedy behavior.
Simulation Results
Success Rate (SR) and Success weighted by Path Length (SPL) across four benchmarks; mean over 10 seeds.
Method
Corridor
Room
Complex-1
Complex-2
SR%
SPL
SR%
SPL
SR%
SPL
SR%
SPL
HiPAN (Ours)
98.5
93.2
98.4
88.8
94.4
89.3
94.7
83.6
HiPAN w/o Posture
98.4
93.1
94.5
74.1
74.2
69.1
73.1
66.2
HiPAN w/o PGCL
97.8
88.7
76.9
69.0
78.1
68.0
74.5
66.5
Bug Algorithm
91.1
58.9
88.1
67.4
23.8
20.1
21.4
20.4
Wall-Following
51.9
31.7
84.5
59.1
22.4
19.8
20.2
19.7
Flat-RL
82.0
71.5
43.8
39.7
45.3
42.1
43.7
40.1
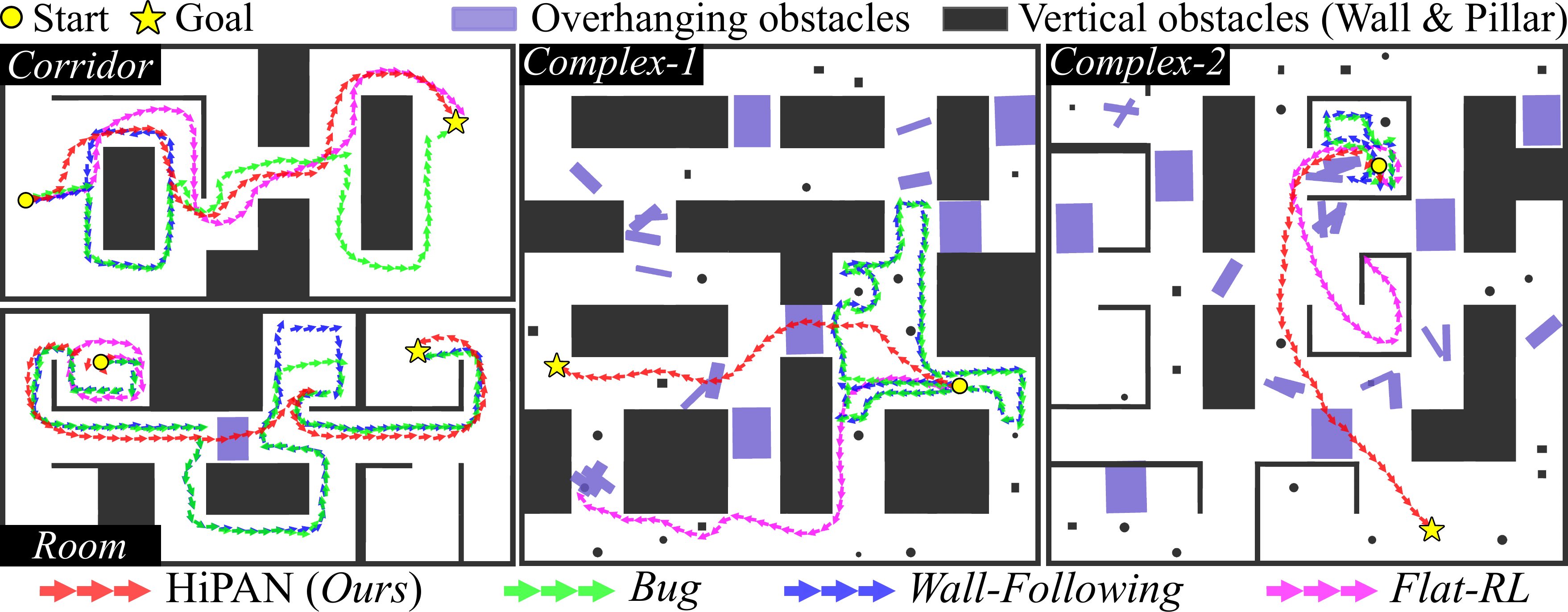
Qualitative trajectories. HiPAN (red) reliably reaches the goal, whereas Bug (green), Wall-Following (blue), and Flat-RL (magenta) frequently detour or become trapped.
Simulation video. Rollouts across the four procedurally generated benchmarks — Corridor, Room, Complex-1, and Complex-2 — spanning dead-ends, enclosed rooms, overhanging obstacles, and cluttered layouts.
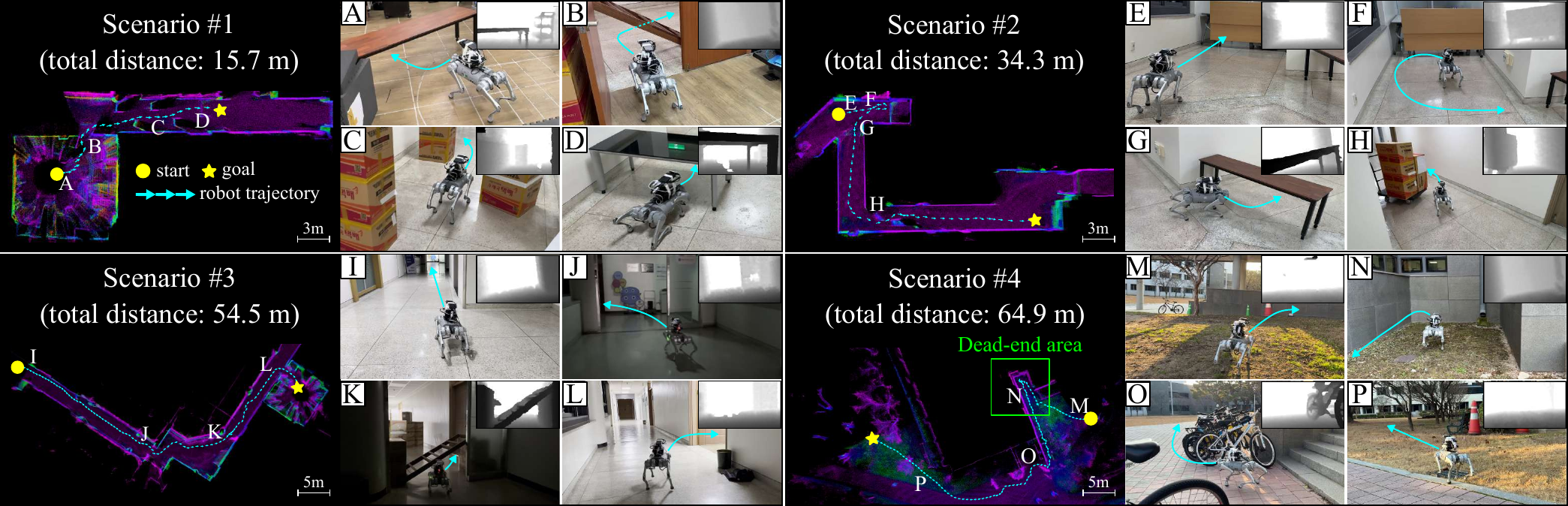
Real-World Validation
Robot trajectories (cyan) from start (circle) to goal (star) overlaid on LiDAR maps (visualization only). Four scenarios validate posture adaptation, dead-end recovery, illumination robustness, and outdoor generalization.
Scenario 1 — Indoor Clutter
Posture-adaptive navigation among tables, ladders, and box piles.
Scenario 2 — Dead-End Recovery
Backtracking from a dead-end corridor, then continuing toward the goal.
Scenario 3 — Illumination Changes
Robust operation under abrupt lighting loss at a doorway.
Scenario 4 — Outdoors
Direct sunlight, uneven terrain, and unseen obstacles (bicycles, cones).
BibTeX
@misc{jeong2026hipanhierarchicalpostureadaptivenavigation,
title={HiPAN: Hierarchical Posture-Adaptive Navigation for Quadruped Robots in Unstructured 3D Environments},
author={Jeil Jeong and Minsung Yoon and Seokryun Choi and Heechan Shin and Taegeun Yang and Sung-eui Yoon},
year={2026},
eprint={2604.26504},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2604.26504}
}